cgroup 内存子系统
cgroup 内存子系统
内存按用途分类
- 用户空间的匿名映射页(Anonymous pages in User Mode address spaces),比如调用
malloc分配的内存,以及使用MAP_ANONYMOUS的mmap;当系统内存不够时,内核可以将这部分内存交换出去。 - 用户空间的文件映射页(Mapped pages in User Mode address spaces),包含map file
和map tmpfs;前者比如指定文件的mmap,后者比如IPC共享内存;当系统内存不够
时,内核可以回收这些页,但回收之前可能需要与文件同步数据。 - 文件缓存(page in page cache of disk file);发生在程序通过普通的read/write
读写文件时,当系统内存不够时,内核可以回收这些页,但回收之前可能需要与文件同步数据。 - buffer pages,属于page cache;比如读取块设备文件。
其中1和2是算作进程的RSS,3和4属于page cache。
内存子系统的作用
- Accounting memory usage under cgroup, Memory here is physical memory.
- Limit memory usage under user specified value.
- If necessary, cull(pageout) memory under it.
内存子系统的内核实现
memory子系统是通过linux的resource counter机制实现的。resource counter是内核为
子系统提供的一种资源管理机制。这个机制的实现包括了用于记录资源的数据结构和
相关函数。Resource counter定义了一个res_counter的结构体来管理特定资源,定义如下:
struct res_counter {
//usage 用于记录当前已使用的资源
unsigned long long usage;
//max_usage 用于记录使用过的最大资源量
unsigned long long max_usage;
//limit 用于设置资源的使用上限,进程组不能使用超过这个限制的资源
unsigned long long limit;
//soft_limit 用于设定一个软上限,进程组使用的资源可以超过这个限制
unsigned long long soft_limit;
//failcnt 用于记录资源分配失败的次数,管理可以根据这个记录,调整上限值。
unsigned long long failcnt;
spinlock_t lock;
//Parent 指向父节点,这个变量用于处理层次性的资源管理。
struct res_counter *parent;
};
相关函数:
void res_counter_init(struct res_counter *counter, struct res_counter *parent)
int res_counter_charge(struct res_counter *counter, unsigned long val,struct res_counter **limit_fail_at)
void res_counter_uncharge(struct res_counter *counter, unsigned long val)
函数res_counter_charge作用就是记录进程组使用的资源。
在这个函数中:
for (c = counter; c != NULL; c = c->parent) {
spin_lock(&c->lock);
ret = res_counter_charge_locked(c, val);
spin_unlock(&c->lock);
if (ret < 0) {
*limit_fail_at = c;
goto undo;
}
}
在这个循环里,从当前res_counter开始,从下往上逐层增加资源的使用量。
res_counter_charge_locked这个函数,这个函数顾名思义就是在加锁的情况
下增加使用量。实现如下:
if (counter->usage + val > counter->limit) {
counter->failcnt++;
ret = -ENOMEM;
if (!force)
return ret;
}
counter->usage += val;
if (counter->usage > counter->max_usage)
counter->max_usage = counter->usage;
首先判断是否已经超过使用上限,如果是的话就增加失败次数,返回相关代码;
否则就增加使用量的值,如果这个值已经超过历史最大值,则更新最大值。
内存子系统定义了一个叫mem_cgroup的结构体来管理cgroup相关的内存使用信息。
struct mem_cgroup {
/* cgroup_subsys_state成员,便于task或cgroup获取mem_cgroup。*/
struct cgroup_subsys_state css;
/* 两个res_counter成员,分别用于管理memory资源和memory+swap资源 */
struct res_counter res;
struct res_counter memsw;
struct mem_cgroup_lru_info info;
spinlock_t reclaim_param_lock;
int prev_priority;
int last_scanned_child;
/* use_hierarchy则用来标记资源控制和记录时是否是层次性的。*/
bool use_hierarchy;
atomic_t oom_lock;
atomic_t refcnt;
unsigned int swappiness;
/* oom_kill_disable则表示是否使用oom-killer。*/
int oom_kill_disable;
/*
如果memsw_is_minimum为true,则res.limit=memsw.limit,即当进程组使用的
内存超过memory的限制时,不能通过swap来缓解。
*/
bool memsw_is_minimum;
struct mutex thresholds_lock;
struct mem_cgroup_thresholds thresholds;
struct mem_cgroup_thresholds memsw_thresholds;
/* oom_notify指向一个oom notifier event fd链表。*/
struct list_head oom_notify;
unsigned long move_charge_at_immigrate;
struct mem_cgroup_stat_cpu *stat;
};
内核的实现是通过mm_struct知道属于它的进程,通过函数mem_cgroup_from_task()
得到mem_cgroup,然后进行内存统计。
cgroup的任务和内存子系统之间的联系
mm_struct==>task_struct==>css_set==>cgroup_subsys_state=>mem_cgroup==>res
mem_cgroup_from_task ==>
mem_cgroup_from_css ==>
task_css ==>
task_css_check
struct mem_cgroup *mem_cgroup_from_css(struct cgroup_subsys_state *s)
{
return s ? container_of(s, struct mem_cgroup, css) : NULL;
}
Charge/Uncharge
Memory cgroup accounts usage of memory. There are roughly 2 operations, charge/uncharge.
- Charge
- (Memory) Usage += PAGE_SIZE
- Free/cull memory if usage hit limits
- Check a page as “This page is charged”
应用场景一
在page fault发生时的情况:
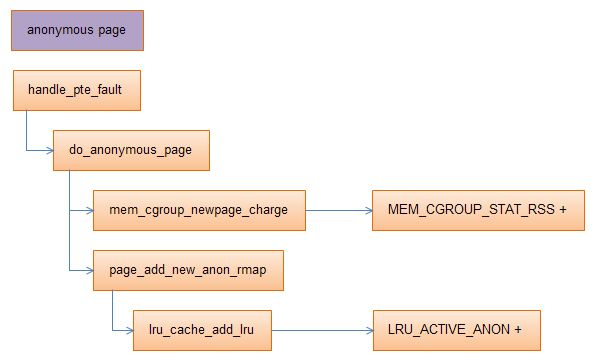
而mem_cgroup_newpage_charge()的调用如下:
mem_cgroup_newpage_charge==>
mem_cgroup_charge_common==>
__mem_cgroup_try_charge==>
mem_cgroup_do_charge==>
mem_cgroup_reclaim
mem_cgroup_oom
__mem_cgroup_commit_charge
通过上面的调用关系可以知道,在charge中有回收操作。
应用场景二
在文件读写操作过程中会产生缓存,cgroup同样会处理。
/* This function is used to add a page to the pagecache. */
add_to_page_cache_locked==>
mem_cgroup_cache_charge==>
mem_cgroup_charge_common==>
__mem_cgroup_try_charge
__mem_cgroup_commit_charge
__mem_cgroup_try_charge_swapin
__mem_cgroup_try_charge_swapin
- Uncharge
- (Memory) Usage -= PAGE_SIZE
- Remove the check
页面回收
- 如果内核检测到某个操作期间内存严重不足,将调用try_to_free_pages。该函数检查当前内存域中所有页,并释放最不常用的那些。
- 一个后台守护进程,名为kswaped,会定期检查内存使用情况,并检测即将发生的内存不足。可使用该守护进程换出页,作为预防措施,
以防内核在执行其他操作期间发生内存不足。
页面回收流程如下:
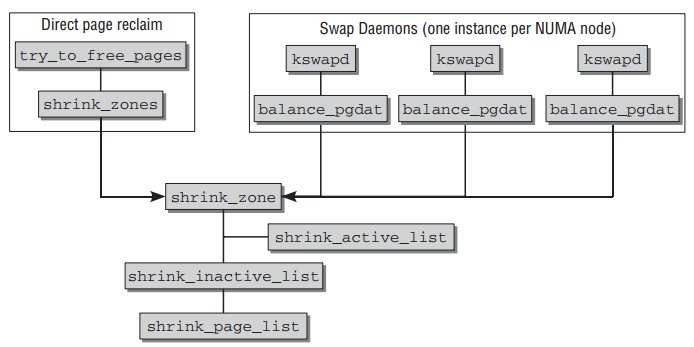
Global VM’s memory reclaim logic is triggered at memory shortage in a zone.
- It’s important where we reclaim memory from and the kernel may have to
reclaim continuous pages. - Kswapd works.
- Slabs are dropped.
Memcg’s memory reclaim is triggered at memory usage hits its limit.
- Just reducing memory is important. No care about placement of pages.
- No kswapd help (now)
- No slab drop.
unsigned long try_to_free_mem_cgroup_pages(struct mem_cgroup *memcg,
gfp_t gfp_mask,
bool noswap)
{
struct zonelist *zonelist;
unsigned long nr_reclaimed;
int nid;
struct scan_control sc = {
.may_writepage = !laptop_mode,
.may_unmap = 1,
.may_swap = !noswap,
.nr_to_reclaim = SWAP_CLUSTER_MAX,
.order = 0,
.priority = DEF_PRIORITY,
.target_mem_cgroup = memcg,
.nodemask = NULL, /* we don't care the placement */
.gfp_mask = (gfp_mask & GFP_RECLAIM_MASK) |
(GFP_HIGHUSER_MOVABLE & ~GFP_RECLAIM_MASK),
};
sc的成员变量nodemask为NULL,说明可以对所有内存node进行页面回收。
应用中需要注意的要素
- cgroup统计内存的时刻为进程加入到cgroup,而在这之前进程使用内存不统计。
- cgroup内存子系统只是设置了使用的上线,当需要使用内存的时候需要临时分配,
而不是提前分配准备。 - cgroup并没有创造出一个隔离的环境,操作系统可以回收cgroup的内存。
需要理解的问题:
- 命名空间 和 如何实现Docker ?
- 为什么要强调是以线程统计?
- 内核/proc统计内存的方法?