理解cgroup实现
理解cgroup实现
cgroup 概述
cgroups是Linux内核提供的一种机制,这种机制可以根据特定的行为,把一系列系统任务
及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一
个统一的框架。实现cgroups的主要目的是为不同用户层面的资源管理,提供一个统一化
的接口。从单个进程的资源控制到操作系统层面的虚拟化。Cgroups提供了以下四大功能。
- 资源限制(Resource Limitation):cgroups可以对进程组使用的资源总额进行限制。
如设定应用运行时使用内存的上限,一旦超过这个配额就发出OOM(Out of Memory)。 - 优先级分配(Prioritization):通过分配的CPU时间片数量及硬盘IO带宽大小,实际上
就相当于控制了进程运行的优先级。 - 资源统计(Accounting): cgroups可以统计系统的资源使用量,如CPU使用时长、内
存用量等等,这个功能非常适用于计费。 - 进程控制(Control):cgroups可以对进程组执行挂起、恢复等操作。
cgroup 术语表
- task(任务):cgroups的术语中,task就表示系统的一个进程。
- cgroup(控制组):cgroups 中的资源控制都以cgroup为单位实现。cgroup
表示按某种资源控制标准划分而成的任务组,包含一个或多个子系统。一个
任务可以加入某个cgroup,也可以从某个cgroup迁移到另外一个cgroup。 - subsystem(子系统):cgroups中的subsystem就是一个资源调度控制器
(Resource Controller)。比如CPU子系统可以控制CPU时间分配,内存
子系统可以限制cgroup内存使用量。 - hierarchy(层级树):hierarchy由一系列cgroup以一个树状结构排列而成,
每个hierarchy通过绑定对应的subsystem进行资源调度。hierarchy中的
cgroup节点可以包含零或多个子节点,子节点继承父节点的属性。整个系统
可以有多个hierarchy。
cgroup的基本规则
传统的Unix进程管理,实际上是先启动init进程作为根节点,再由init节点创建
子进程作为子节点,而每个子节点由可以创建新的子节点,如此往复,形成一个
树状结构。而cgroups也是类似的树状结构,子节点都从父节点继承属性。它们
最大的不同在于,系统中cgroup构成的hierarchy可以允许存在多个。如果进程
模型是由init作为根节点构成的一棵树的话,那么cgroups的模型则是由多个
hierarchy构成的森林。这样做的目的也很好理解,如果只有一个hierarchy,
那么所有的task都要受到绑定其上的subsystem的限制,会给那些不需要这些限制
的task造成麻烦。
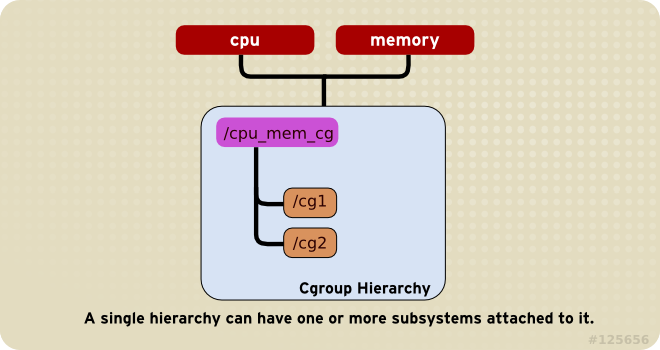
规则1 同一层级树可以附加多个子系统
同一个hierarchy可以附加一个或多个subsystem。如下图,cpu和memory的
subsystem附加到了一个hierarchy。
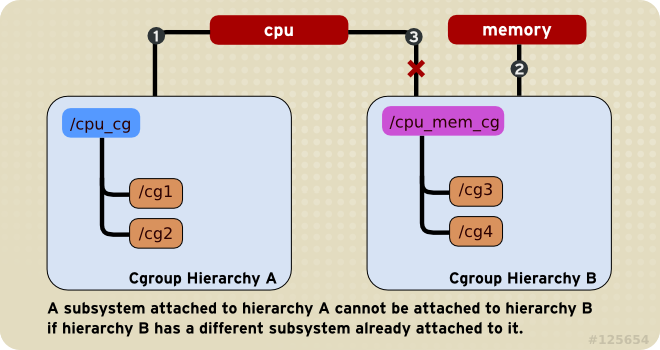
规则2 任何子系统最多可附加到一个层级树中
一个subsystem可以附加到多个hierarchy,当且仅当这些hierarchy只有这唯一
一个subsystem。如下图,小圈中的数字表示subsystem附加的时间顺序,CPU subsystem
附加到hierarchy A的同时不能再附加到hierarchy B,因为hierarchy B已经附加了
memory subsystem。如果hierarchy B与hierarchy A状态相同,没有附加过
memory subsystem,那么CPU subsystem同时附加到两个hierarchy是可以的。
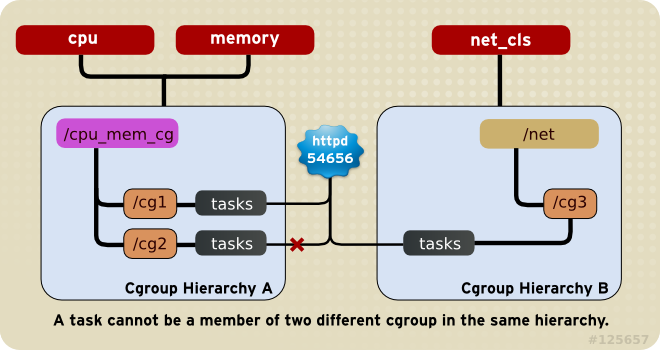
规则3 任务只能存在层级树中的唯一cgroup中
系统每次新建一个hierarchy时,该系统上的所有task默认构成了这个新建的
hierarchy的初始化cgroup,这个cgroup也称为root cgroup。对于你创建的
每个hierarchy,task只能存在于其中一个cgroup中,即一个task不能存在于
同一个hierarchy的不同cgroup中,但是一个task可以存在在不同hierarchy
中的多个cgroup中。如果操作时把一个task添加到同一个hierarchy中的另
一个cgroup中,则会从第一个cgroup中移除。在下图中可以看到,httpd
进程已经加入到hierarchy A中的/cg1而不能加入同一个hierarchy中的/cg2,
但是可以加入hierarchy B中的/cg3。实际上不允许让任务加入同一个
hierarchy中的多个cgroup是为了防止出现矛盾,如CPU subsystem为/cg1
分配了30%,而为/cg2分配了50%,此时如果httpd在这两个cgroup中,就会
出现矛盾。
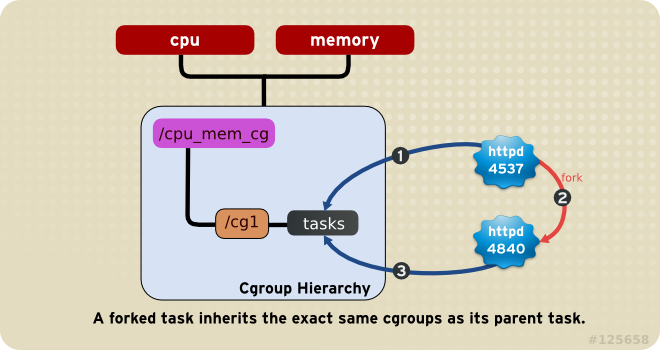
规则4 子进程继承父进程的cgroup属性
进程(task)在fork自身时创建的子任务(child task)默认与原task在
同一个cgroup中,但是child task允许被移动到不同的cgroup中。即fork
完成后,父子进程间是完全独立的。如下图中,小圈中的数字表示task
出现的时间顺序,当httpd刚fork出另一个httpd时,在同一个hierarchy中
的同一个cgroup中。但是随后如果PID为4840的httpd需要移动到其他cgroup
也是可以的,因为父子任务间已经独立。总结起来就是:初始化时子任务与
父任务在同一个cgroup,但是这种关系随后可以改变。
cgroup实现
cgroups的实现本质上是给系统进程挂上钩子(hooks),当task运行的过程
中涉及到某个资源时就会触发钩子上所附带的subsystem进行检测,最终根据
资源类别的不同使用对应的技术进行资源限制和优先级分配。
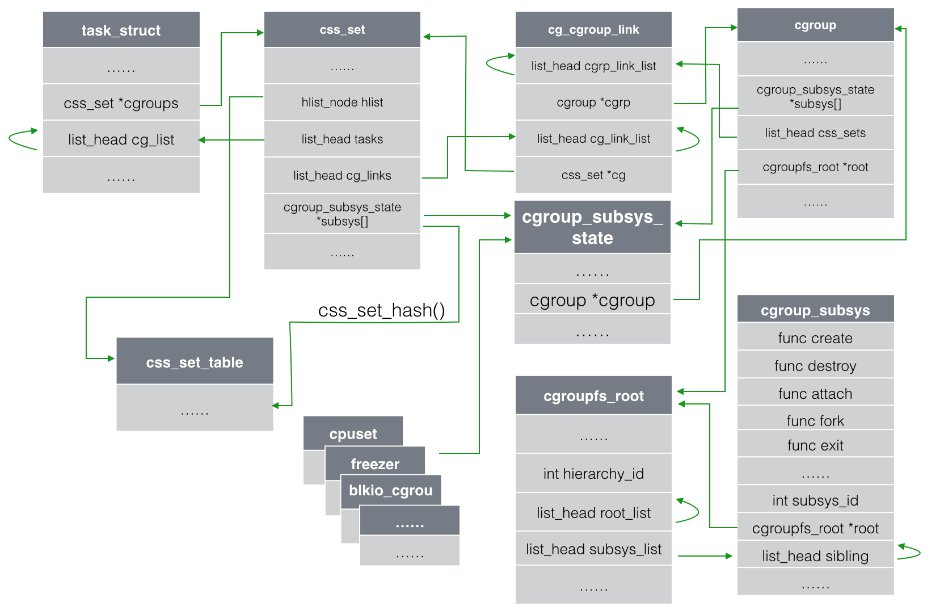
Linux中管理task进程的数据结构为 task_struct(包含所有进程管理的信息),
其中与cgroup相关的字段主要有两个,一个是css_set *cgroups,表示指向
css_set(包含进程相关的cgroups信息)的指针,一个task只对应一个css_set结构,
但是一个css_set可以被多个task使用。另一个字段是list_head cg_list,是一个
链表的头指针,这个链表包含了所有的链到同一个css_set的task进程(在图中使用
的回环箭头,均表示可以通过该字段找到所有同类结构,获得信息)。
每个css_set结构中都包含了一个指向 cgroup_subsys_state(包含进程与一个
特定子系统相关的信息)的指针数组。cgroup_subsys_state则指向了cgroup结构
(包含一个cgroup的所有信息),通过这种方式间接的把一个进程和cgroup
联系了起来,如下图。
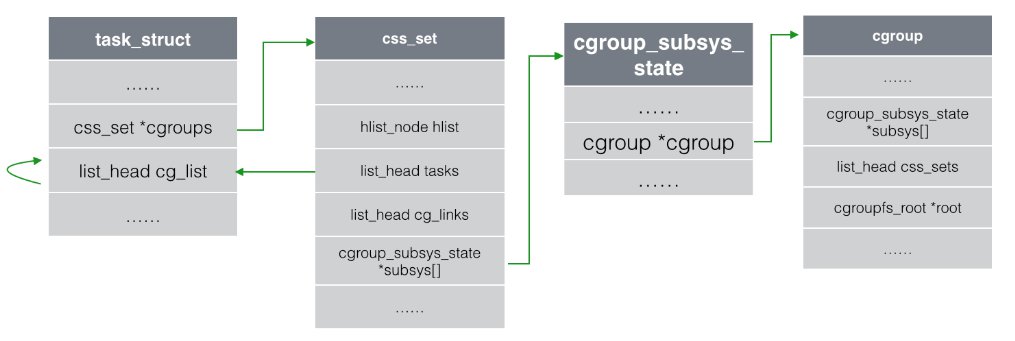
另一方面,cgroup结构体中有一个list_head css_sets字段,它是一个头指针,
指向由cg_cgroup_link(包含cgroup与task之间多对多关系的信息)形成的链表。
由此获得的每一个cg_cgroup_link都包含了一个指向css_set *cg字段,指向了
每一个task的css_set。css_set结构中则包含tasks头指针,指向所有链到
此css_set的task进程构成的链表。至此,我们就明白如何查看在同一个
cgroup中的task有哪些了,如下图。
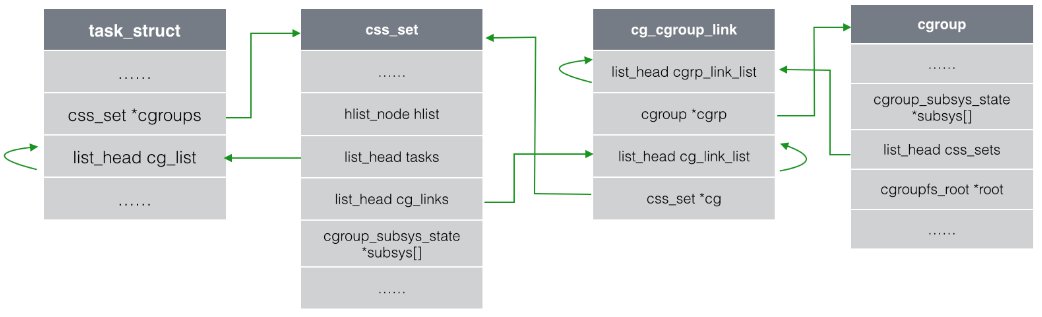
那么为什么要使用cg_cgroup_link结构体呢?因为task与cgroup之间是多对多的关系。
熟悉数据库的读者很容易理解,在数据库中,如果两张表是多对多的关系,那么如果
不加入第三张关系表,就必须为一个字段的不同添加许多行记录,导致大量冗余。
通过从主表和副表各拿一个主键新建一张关系表,可以提高数据查询的灵活性和效率。
而一个task可能处于不同的cgroup,只要这些cgroup在不同的hierarchy中,并且
每个hierarchy挂载的子系统不同;另一方面,一个cgroup中可以有多个task,这是
显而易见的,但是这些task因为可能还存在在别的cgroup中,所以它们对应的css_set
也不尽相同,所以一个cgroup也可以对应多个css_set。在系统运行之初,内核的
主函数就会对root cgroups和css_set进行初始化,每次task进行fork/exit时,都会
附加(attach)/分离(detach)对应的css_set。综上所述,添加cg_cgroup_link
主要是出于性能方面的考虑,一是节省了task_struct结构体占用的内存,二是提升
了进程fork()/exit()的速度。
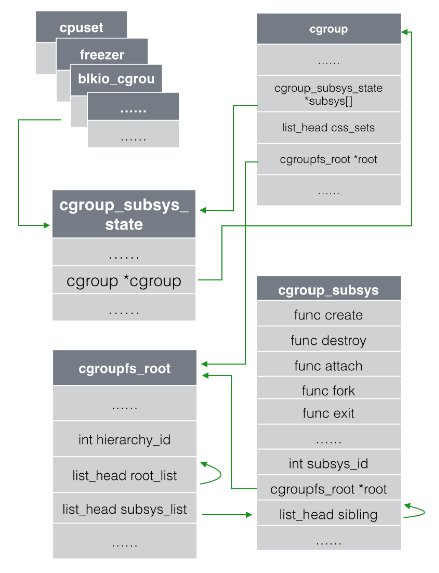
定义子系统的结构体是cgroup_subsys,在下图中可以看到,cgroup_subsys中定义了
一组函数的接口,让各个子系统自己去实现,类似的思想还被用在了cgroup_subsys_state
中,cgroup_subsys_state并没有定义控制信息,只是定义了各个子系统都需要用到的
公共信息,由各个子系统各自按需去定义自己的控制信息结构体,最终在自定义的
结构体中把cgroup_subsys_state包含进去,然后内核通过container_of(这个宏可以
通过一个结构体的成员找到结构体自身)等宏定义来获取对应的结构体。
cgroup文件系统的实现
Linux VFS是所谓的虚拟文件系统转换,是一个内核软件层,用来处理与Unix标准文件
系统的所有系统调用。VFS对用户提供统一的读写等文件操作调用接口,当用户调用
读写等函数时,内核则调用特定的文件系统实现。具体而言,文件在内核内存中是
一个file数据结构来表示的。这个数据结构包含一个f_op的字段,该字段中包含了
一组指向特定文件系统实现的函数指针。当用户执行read()操作时,内核调用
sys_read(),然后sys_read()查找到指向该文件属于的文件系统的读函数指针,并
调用它,即file->f_op->read()。
VFS 文件系统定义了以下对象模型:
- 超级块对象(superblock object):存放已安装文件系统的有关信息。
- 索引节点对象(inode object):存放关于具体文件的一般信息。
- 文件对象( file object):存放打开文件与进程之间的交互信息
- 目录项对象(dentry object):存放目录项与对应文件进行链接的有关信息。